[Python] 판다스(pandas)_6.operator - 연산자, function - 데이터 프레임 함수
#정리
#08operator - 연산자
#DataFrame 연산함수(add,sub,mul,div)
- sum_df = df01 + df02
- add_df = df01.add(df02,fill_value=0)- sub_df = df01.sub(df02,fill_value=0)
- mul_df = df01.mul(df02,fill_value=0)
- div_df = df01.div(df02,fill_value=0)
#DataFrame 데이터 값 일괄 변경 연산 (broadcasting)
- print(df01 + 100)
- print(df01 - 100)
- print(df01 * 100)
- print(df01 / 100)
#(활용)모든 셀에 서울 [11 12 13] 값을 활용하여 연산
- print(df01 + df01.loc['서울'])
- print(df01 - df01.loc['서울'])
- print(df01 * df01.loc['서울'])
- print(df01 / df01.loc['서울'])
#09function - 함수
#NaN처리함수 : dropna(),dropna(how-'all'),fillna(value)
- NaN : Not a Number - 누락된 값 또는 NA
- print(df.isnull()) #null값을 True로 반환한다.
- print(df.notnull()) #null값을 False로 반환한다.
- print(df.dropna()) # 1개라도 null 있는 행 삭제
- print(df.dropna(how='all')) #모두 null인 행 삭제
- print(df.fillna(88)) #null값을 지정값으로 대체
#df.sum( ) : 합산값
- print(df.sum(skipna=True)) #nan을 0으로 대체하여 합산 값을 반환한다(skipna=true 삭제 가능).
- print(df.sum(skipna=False)) #하나라도 nan이면 결과는 nan
- print(df.sum(axis=1)) #컬럼이 아닌 각 인덱스(행)의 합을 반환한다.- print(df.sum(axis=1,skipna=False)) #인덱스별 합산, 하나라도 nan이면 결과는 nan
#df.mean( ) : 평균값
- print(df.mean()) #nan은 평균 계산에서 제외
- print(df.mean(axis=1)) #nan의 평균은 nan이 된다.
- print(df.mean(axis=1,skipna=False)) #1개라도 nan이면 nan으로 반환
#df.idxmin(),idxmax() : 최소,최대값을 가진 인덱스 찾기
- print(df.idxmin()) #0 >> 최소값을 가진 인덱스([0]) 반환
- print(df.idxmax()) #3 >> 최대값을 가진 인덱스([3]) 반환
#df.describe() : 통계량 반환
- print(df.describe())#각 열의 통계량(갯수, 평균, 편차, 분산 등) 반환
#df.info() : 데이터 정보 반환
- print(df.info())#각 열의 데이터 정보(행렬 형태, 타입, 값, 용량 등)
#08operator - 연산자
#DataFrame 연산함수(add,sub,mul,div)
- sum_df = df01 + df02
- add_df = df01.add(df02,fill_value=0)
- sub_df = df01.sub(df02,fill_value=0)
- mul_df = df01.mul(df02,fill_value=0)
- div_df = df01.div(df02,fill_value=0)
#DataFrame 데이터 값 일괄 변경 연산 (broadcasting)
- print(df01 + 100)
- print(df01 - 100)
- print(df01 * 100)
- print(df01 / 100)
#(활용)모든 셀에 서울 [11 12 13] 값을 활용하여 연산
- print(df01 + df01.loc['서울'])
- print(df01 - df01.loc['서울'])
- print(df01 * df01.loc['서울'])
- print(df01 / df01.loc['서울'])


--예문 코드 보기--
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
#from numpy import *
#from pandas import Series,DataFrame
# >> Series,DataFrame 는 pd.Series라고 안적고, pd. 까지만 적어도 된다.
print("numpy version",pd.__version__) #pandas version check
print("---------------")
print("--DataFrame 연산함수(add,sub,mul,div)--------")
arr = np.arange(11,11+9).reshape(3,3)
df01 = pd.DataFrame(arr
,columns=['1차','2차','3차']
,index=['서울','대전','부산'])
print(df01)
print("---------------")
arr = np.arange(1,1+12).reshape(4,3)
df02 = pd.DataFrame(arr
,columns=['1차','2차','3차']
,index=['서울','대전','부산','대구'])
print(df02)
print("---df01 + df02----")
sum_df = df01 + df02
print(sum_df)
print("---add(df02,fill_value=0)---")
add_df = df01.add(df02,fill_value=0)
print(add_df)
print("---sub(df02,fill_value=0)---")
sub_df = df01.sub(df02,fill_value=0)
print(sub_df)
print("---mul(df02,fill_value=0)---")
mul_df = df01.mul(df02,fill_value=0)
print(mul_df)
print("---div(df02,fill_value=0)---")
div_df = df01.div(df02,fill_value=0)
print(div_df)
print("---df01 ---")
print(df01)
print("---df01 + ---")
print(df01 + 100)
print("---df01 - ---")
print(df01 - 100)
print("---df01 *---")
print(df01 * 100)
print("---df01 /---")
print(df01 / 100)
print("---df01['1차']---")
print(df01['1차'])
print("---loc['서울']---")
print(df01.loc['서울'])
print("---iloc[0] = loc['서울']---")
print(df01.iloc[0]) #index loc
print("---모든 셀에서 서울 [11 12 13] 가지고 연산 ")
print(df01 + df01.loc['서울'])
print(df01 - df01.loc['서울'])
print(df01 * df01.loc['서울'])
print(df01 / df01.loc['서울'])
#09function - 함수
#NaN처리함수 : dropna(),dropna(how-'all'),fillna(value)
- NaN : Not a Number - 누락된 값 또는 NA
- print(df.isnull()) #null값을 True로 반환한다.
- print(df.notnull()) #null값을 False로 반환한다.
- print(df.dropna()) # 1개라도 null 있는 행 삭제
- print(df.dropna(how='all')) #모두 null인 행 삭제
- print(df.fillna(88)) #null값을 지정값으로 대체
#df.sum( ) : 합산값
- print(df.sum(skipna=True)) #nan을 0으로 대체하여 합산 값을 반환한다(skipna=true 삭제 가능).
- print(df.sum(skipna=False)) #하나라도 nan이면 결과는 nan
- print(df.sum(axis=1)) #컬럼이 아닌 각 인덱스(행)의 합을 반환한다.
- print(df.sum(axis=1,skipna=False)) #인덱스별 합산, 하나라도 nan이면 결과는 nan
#df.mean( ) : 평균값
- print(df.mean()) #nan은 평균 계산에서 제외
- print(df.mean(axis=1)) #nan의 평균은 nan이 된다.
- print(df.mean(axis=1,skipna=False)) #1개라도 nan이면 nan으로 반환
#df.idxmin(),idxmax() : 최소,최대값을 가진 인덱스 찾기
- print(df.idxmin()) #0 >> 최소값을 가진 인덱스([0]) 반환
- print(df.idxmax()) #3 >> 최대값을 가진 인덱스([3]) 반환
#df.describe() : 통계량 반환
- print(df.describe())#각 열의 통계량(갯수, 평균, 편차, 분산 등) 반환
#df.info() : 데이터 정보 반환
- print(df.info())#각 열의 데이터 정보(행렬 형태, 타입, 값, 용량 등)

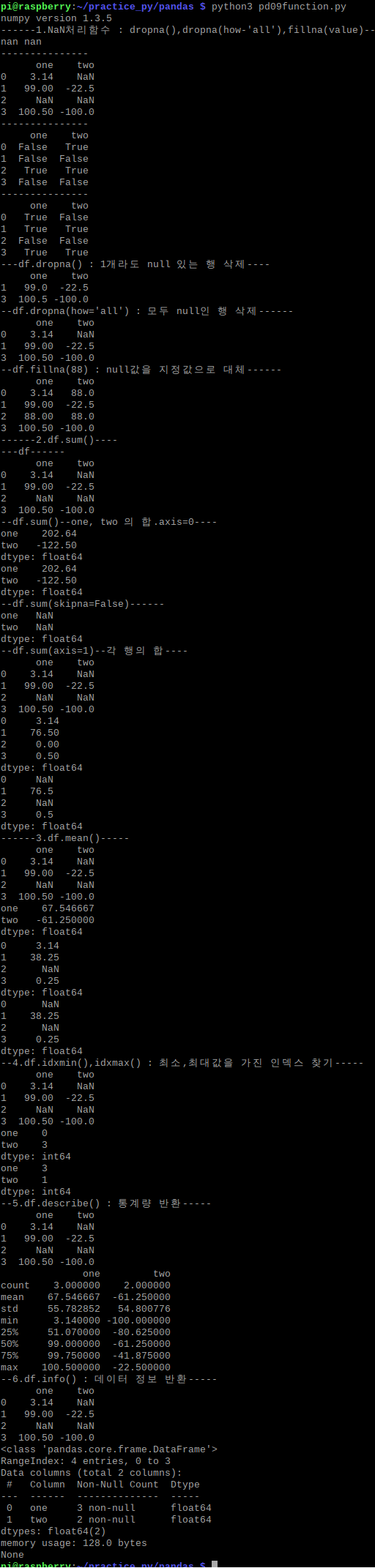
--예문 코드 보기--
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
#from numpy import *
#from pandas import Series,DataFrame
# >> Series,DataFrame 는 pd.Series라고 안적고, pd. 까지만 적어도 된다.
print("numpy version",pd.__version__) #pandas version check
print("------1.NaN처리함수 : dropna(),dropna(how-'all'),fillna(value)---")
print(np.NaN,np.nan) #NaN : Not a Number - 누락된 값 또는 NA
print("---------------")
arr = [
[3.14, np.nan],
[99, -22.5],
[np.nan, np.nan],
[100.5, -100],
]
df = pd.DataFrame(arr, columns=['one','two'])
print(df)
print("---------------")
print(df.isnull()) #null - True
print("---------------")
print(df.notnull()) #null - False
print("---df.dropna() : 1개라도 null 있는 행 삭제----")
print(df.dropna())
print("--df.dropna(how='all') : 모두 null인 행 삭제------")
print(df.dropna(how='all'))
print("--df.fillna(88) : null값을 지정값으로 대체------")
print(df.fillna(88))
print("------2.df.sum()----")
print("---df------")
print(df)
print("--df.sum()--one, two 의 합.axis=0----")
print(df.sum()) #nan=0 자동 처리
print(df.sum(skipna=True)) #default
print("--df.sum(skipna=False)------")
print(df.sum(skipna=False)) #하나라도 nan이면 결과는 nan
print("--df.sum(axis=1)--각 행의 합----")
print(df)
print(df.sum(axis=1))
print(df.sum(axis=1,skipna=False))
print("------3.df.mean()-----")
print(df)
print(df.mean()) #nan은 평균 계산에서 제외
print(df.mean(axis=1)) #nan의 평균은 nan이 된다.
print(df.mean(axis=1,skipna=False)) #1개라도 nan이면 nan으로 반환
print("--4.df.idxmin(),idxmax() : 최소,최대값을 가진 인덱스 찾기-----")
print(df)
print(df.idxmin())
print(df.idxmax())
print("--5.df.describe() : 통계량 반환-----")
print(df)
print(df.describe())#각 열의 통계량 반환
print("--6.df.info() : 데이터 정보 반환-----")
print(df)
print(df.info())#각 열의 데이터 정보