# 정리
** $@ - 실행할 때 온 인수(argument)를 배열로 받겠다.
** $sleep - 명령문이 실행 될 때 작성 시간만큼 딜레이된다. (단위 : 초,sec)
** $cat > 파일명 <<END -파일내용- END을 이용하여 파일을 만들 수 있다.
# Array 행렬
(1. Basic)
//행렬에는 index array 와 associative array이 있다.
- index array - 순서가 있는 행렬
- associative array - 순서는 없지만, 키와 값이 연결된 행렬 >> 맵핑이 가능함
//${arr[@]} / ${arr[*]} - 데이터 모두 나열
//${!arr[@]}} / ${!arr[*]} - 인덱스 모두 나열
//${#arr[@]} / ${#arr[@]} - 배열 길이 (총 데이터 갯수)
(2. declare 선언)
//$declare 선언을 통한 배열 생성
- declare -a /-A 변수A >> 변수A를 일반 변수가 아닌 배열 변수로 사용하겠다는 선언이다.
- (-a 옵션) - index array 선언 (결과 값은 위의 기본 코드의 결과 참조)
- (-A 옵션) - associative array 선언
(3. 데이터 길이 확인 / 데이터 삭제 / 데이터 삽입)
//${#~}으로 데이터 길이 확인 가능
- ${#행렬[인덱스]}로 특정 데이터 길이 확인 가능
- ${#변수이름}으로 특정 변수 안의 데이터 길이 확인 가능
//데이터 지우기 (arr=() / unset)
//특정 인덱스에 데이터값을 넣을 수 있다.
- 배열이름=([인덱스]=값 [인덱스]=값 [인덱스]=값) 형태로 넣는다.
(4. 데이터 속 띄어쓰기 다루기)
//띄어쓰기가 있는 데이터는 " "을 감싸줘야 한 줄에 출력할 수 있다.
- 데이터의 실제 갯수는 같아도, 출력은 다른 데이터처럼 분해되어 출력된다.
- for in으로 출력할 때도 " "로 행렬을 감싸주어야 데이터가 붙어서 출력된다.
**숫자는 띄어쓰면 다른 데이터지만, 문자는 띄어쓰기가 있는 문장일 수 있기 때문에 문자 데이터를 받아올 때는 " "를 감싸서 받아오는 것이 안전하다.
(5. while + read)
//while read 변수 - do - done < 파일명 을 뼈대로 만든다.
//while read를 이용해서 띄어쓰기와 상관없이 줄 단위로 읽어올 수 있다.
- (변수가 1개) 줄 전체를 하나의 변수에 넣어 읽는다.
- (변수가 여러로 할당) 띄어쓴 단어 별로 각 변수에 넣어 읽는다(마지막 실행문 참조).
**for문에서는 띄어쓴 단어별로 혹은 텍스트 전체를 묶어서 가져올 수 밖에 없다.
# select_in 선택 분기문
//select 변수 in "1번 반환값" "2번 반환값" ... - do - done 뼈대로 만든다.
- case와 달리 문자로 선택하는 것이 아니라, 숫자로 선택한다.
- 무한루프가 기본이므로, break를 달아주면 좋다.
- $exit - 강제 종료 명령으로 종료 선택지를 만들 수 있다.
# readonly - 상수 선언
//readonly를 앞에 붙여서 사용 - 상수 처리되어 추후에 값을 수정할 수 없다. (JS const / Java final 와 비슷)
- $declare -r : 상수 정의명령으로 $readonly변수명 과 같은 효과를 가진다.
# Array 행렬 - 1. Basic
//행렬에는 index array 와 associative array이 있다.
- index array - 순서가 있는 행렬
- associative array - 순서는 없지만, 키와 값이 연결된 행렬 >> 맵핑이 가능함
//${arr[@]} / ${arr[*]} - 데이터 모두 나열
//${!arr[@]}} / ${!arr[*]} - 인덱스 모두 나열
//${#arr[@]} / ${#arr[@]} - 배열 길이 (총 데이터 갯수)
* $@ - 실행할 때 온 인수(argument)를 배열로 받겠다.
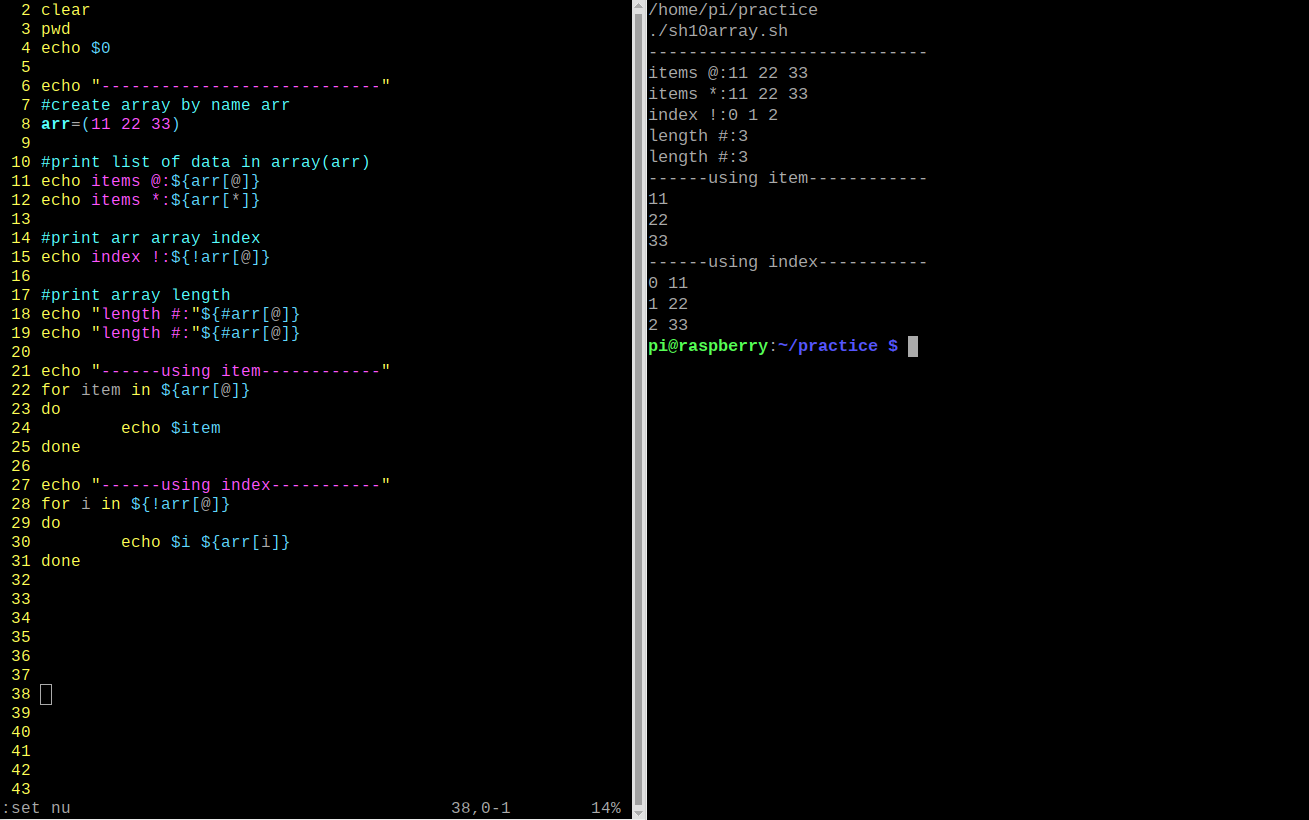
#!/bin/bash
clear
pwd
echo $0
echo "----------------------------"
#create array by name arr
arr=(11 22 33)
#print list of data in array(arr)
echo items @:${arr[@]}
echo items *:${arr[*]}
#print arr array index
echo index !:${!arr[@]}}
#print array length
echo "length #:"${#arr[@]}
echo "length #:"${#arr[@]}
echo "------print item------------"
for item in ${arr[@]}
do
echo $item
done
echo "---print index & item-------"
for i in ${!arr[@]}
do
echo $i ${arr[i]}
done
exit 0
--------------------------------------
# Array 행렬 - 2. declare
//$declare 선언을 통한 배열 생성
- declare -a /-A 변수A >> 변수A를 일반 변수가 아닌 배열 변수로 사용하겠다는 선언이다.
- (-a 옵션) - index array 선언 (결과 값은 위의 기본 코드의 결과 참조)
- (-A 옵션) - associative array 선언


#!/bin/bash
clear
pwd
echo $0
echo "----------index array------------------"
#define variable as indexed array by name arr
declare -a arr
arr=(11 22 33)
#list of data in array(arr)
echo items @:${arr[@]}
echo items *:${arr[*]}
#arr array index
echo index !:${!arr[@]}
#array length
echo "length #:"${#arr[@]}
echo "length #:"${#arr[@]}
echo "using item------------"
for item in ${arr[@]}
do
echo $item
done
echo "using index-----------"
for i in ${!arr[@]}
do
echo $i ${arr[i]}
done
echo "-------associative array--------------"
#declare variable as associative array
declare -A arr
#arrayNmae[key]=value
arr[name]=kim
arr[age]=33
#print items
echo items: ${arr[@]}
#print keys
echo keys: ${!arr[@]}
#similar to java's MAP
echo ${arr[name]} ${arr[age]}
exit 0
--------------------------------------
# Array 행렬 - 3. 데이터 길이 확인 / 데이터 지우기(삭제) / 특정 인덱스에 데이터 넣기(삽입)
//${#~}으로 데이터 길이 확인 가능
- ${#행렬[인덱스]}로 특정 데이터 길이 확인 가능
- ${#변수이름}으로 특정 변수 안의 데이터 길이 확인 가능
//데이터 지우기 (arr=() / unset)
//특정 인덱스에 데이터값을 넣을 수 있다.
- 배열이름=([인덱스]=값 [인덱스]=값 [인덱스]=값) 형태로 넣는다.

#!/bin/bash
clear
pwd
echo $0
echo "----------------------------"
country="korea"
echo "text length:" ${#country}
declare -a arr
arr=(11 "kim" 22)
echo ${arr[@]}
echo ${arr[0]}
echo ${arr[1]}
echo ${arr[2]}
#print length of data in arr[i]
echo ${#arr[0]}
echo ${#arr[1]}
echo ${#arr[2]}
echo "----------------------------"
#delete data in array
#arr=()
unset arr
echo ${arr[@]}
echo ${arr[0]}
echo ${arr[1]}
echo ${arr[2]}
#print length of data in arr[i]
echo ${#arr[0]}
echo ${#arr[1]}
echo ${#arr[2]}
echo "----------------------------"
#input data in specific index
arr=([0]=33 [1]=44 [3]=55)
echo ${#arr[@]}
echo ${arr[0]}
echo ${arr[1]}
echo ${arr[2]}
echo ${arr[3]}
exit 0
--------------------------------------
#mission 1 : 0~100을 행렬 arr에 넣고 echo 혹은 printf로 출력하라.
#mission 2 : 10, 20, ... , 100을 행렬 arr에 넣고 echo 혹은 printf로 출력하라.
**$sleep - 명령문이 실행 될 때 작성 시간만큼 딜레이된다. (단위 : 초,sec)

#!/bin/bash
clear
pwd
echo $0
echo "-----------mission 1-----------------"
arr=()
for i in $(seq 0 100);
do
arr[i]=$i
done
echo ${arr[@]}
echo "-----------mission 1-----------------"
arr=()
for ((i=0;i<101;i++));
do
arr[i]=$i
done
echo ${arr[@]}
echo "-----------mission 2-----------------"
arr=()
for i in $(seq 1 10);
do
arr[i]=$((i*10))
done
echo ${arr[@]}
echo "-----------mission 2-----------------"
arr=()
for ((i=1;i<11;i++));
do
arr[i]=$((i*10))
done
echo ${arr[@]}
echo "-----------sleep-----------------"
#arr=(10,20,30,...,100))
for x in ${arr[@]}
do
echo $x
#delay 1sec each loop
sleep 1
done
exit 0
#mission 3 : kim lee han을 읽어 행렬 arr에 넣고 echo 혹은 printf로 출력하라.

echo "-----------mission 3-----------------"
names=()
for n in $(seq 0 2);
do
read -p "input name: " name
echo $name
names[n]=$name
done
echo ${names[*]}
--------------------------------------
# Array 행렬 - 4. 데이터 속 띄어쓰기 다루기
//띄어쓰기가 있는 데이터는 " "을 감싸줘야 한 줄에 출력할 수 있다.
- 데이터의 실제 갯수는 같아도, 출력은 다른 데이터처럼 분해되어 출력된다.
- for in으로 출력할 때도 " "로 행렬을 감싸주어야 데이터가 붙어서 출력된다.
- 이해가 잘 안된다면, 다음 단락 5. while + read에서 비교하기 위해 파일 생성해서 " "로 불러오는 것도 확인할 것
**숫자는 띄어쓰면 다른 데이터지만, 문자는 띄어쓰기가 있는 문장일 수 있기 때문에 문자 데이터를 받아올 때는 " "를 감싸서 받아오는 것이 안전하다.
//(ex.3참조)한 덩어리의 텍스트가 lslength에 들어있지만, 파일명의 사이에 띄어쓰기가 되어있기 때문에 오히려 줄이 나눠진 목록으로 볼 수 있게된다.
- $ls 명령어의 결과는 한 덩어리의 텍스트(271개의 문자열)로 출력된다는 것을 알 수 있다.

#!/bin/bash
clear
pwd
echo $0
echo "----------------------------"
names=("lee soon shin" "kim" "han")
echo number of data: ${#names[@]}
for name in ${names[@]}
do
echo $name
done
echo "----------------------------"
for name in "${names[@]}"
do
echo $name
done
echo "----------------------------"
#for cheking length of ls command result
lslength=$(ls)
echo length: ${#lslength}
for file_name in $lslength
do
echo $file_name
done
exit 0
--------------------------------------
** $cat > 파일명 <<END -파일내용- END을 이용하여 파일을 만들 수 있다.
# Array 행렬 - 5. while + read
//while read 변수 - do - done < 파일명 을 뼈대로 만든다.
//while read를 이용해서 띄어쓰기와 상관없이 줄 단위로 읽어올 수 있다.
- (변수가 1개) 줄 전체를 하나의 변수에 넣어 읽는다.
- (변수가 여러로 할당) 띄어쓴 단어 별로 각 변수에 넣어 읽는다(마지막 실행문 참조).
**for문에서는 띄어쓴 단어별로 혹은 텍스트 전체를 묶어서 가져올 수 밖에 없다.

#!/bin/bash
clear
pwd
echo $0
echo "----------------------------"
#create text file
cat > sh10temp.txt << END
hello1 linux1 C1 java1
hello2 linux2 C2 java2
hello3 linux3 C3 java3
hello4 linux4 C4 java4
END
ls
echo "----------------------------"
#줄에 상관없이 띄어쓰기 단위로 인식
for txt in $(cat sh10temp.txt);
do
echo $txt
done
echo "----------use\"\"------------"
#cat 명령어로 출력되는 텍스트 전체를 한덩어리로 인식
for txt in "$(cat sh10temp.txt)";
do
echo $txt
done
echo "------while + read----------"
#줄 단위로 덩어리 인식
while read txt
do
echo $txt
done < sh10temp.txt
echo "------while + read----------"
#띄어쓰기 단위로 문자를 인식하여, 각 변수에 문자열 삽입
while read txt1 txt2 txt3 txt4
do
echo $txt1 $txt2 $txt3 $txt4
done < sh10temp.txt
exit 0
# mission 4 : 3명의 성적을 기록하여 파일로 저장하고, 파일 내용을 활용하여 학생별 성적과 총점/평균을 표시하라.
<sh11score.txt> - kim 91 92 93 / lee 81 82 83 / han 71 72 73

clear
pwd
echo $0
echo "----------------------------"
#sh11score.txt
#kim 91 92 93
#lee 81 82 83
#han 71 72 73
#cat create file for
cat > sh11score.txt <<END
kim 91 92 93
lee 81 82 83
han 71 72 73
END
#use "while read" && define variable name
while read name kor eng math
do
#define vars(total/avg/grade) && print values
total=$((kor+eng+math))
avg=$((total/3))
grade="A"
echo $name $kor $eng $math
echo "$name's score total:"$total
echo "$name's score avg:"$avg
if ((avg>=90));then
echo grade="A"
elif ((avg>=80));then
echo grade="B"
elif ((avg>=70));then
echo grade="C"
elif ((avg>=60));then
echo grade="D"
else
echo grade="F"
fi
#input the file name what you want to read
done < sh11score.txt
exit 0
# select_in 선택 분기문
//select 변수 in "1번 반환값" "2번 반환값" ... - do - done 뼈대로 만든다.
- case와 달리 문자로 선택하는 것이 아니라, 숫자로 선택한다.
- 무한루프가 기본이므로, break를 달아주면 좋다.
- $exit - 강제 종료 명령으로 break 대신 선택지 중 하나에 넣어 종료 선택지를 만들 수 있다.

#!/bin/bash
clear
pwd
echo $0
echo "----------------------------"
#create dummy file for practice
touch sh12test.txt
ls
echo "----------------------------"
echo "Do you want to Remove sh12test.txt?"
select yn in "yes" "no" "exit"
do
echo $yn
case $yn in
yes) rm sh12test.txt
echo "removed";;
no) echo "canceled";;
exit) exit
esac
break
done
echo "----------------------------"
ls
exit 0
# readonly - 상수 선언
//readonly를 앞에 붙여서 사용 - 상수 처리되어 추후에 값을 수정할 수 없다. (JS const / Java final 와 비슷)
- $declare -r : 상수 정의명령으로 $readonly변수명 과 같은 효과를 가진다.
- KOR 값이 수정되지 않은 것을 볼 수 있다.

#!/bin/bash
clear
pwd
echo $0
echo "----------------------------"
readonly NAME="kim"
NAME="LEE"
echo $NAME
declare -r KOR="korea"
KOR=100
echo $KOR
exit 0



