#정리
#12linspace - 그래프그리기#그래프 작성 준비
더보기#sudo apt update
#sudo apt upgrade
#sudo apt install python-pip
#sudo apt install python-matplotlib
#wget https://pypi.python.org/packages/source/d/drawnow/drawnow-0.44.tar.gz
#ls >> drawnow-0.44.tar.gz
#tar -zxvf drawnow-0.44.tar.gz
#cd drawnow-0.44
#sudo python setup.py install (python 으로 실행할 것. python3 아님)
#sudo pip install drawnow
#cd ..
#python np12linspace.py#import matplotlib.pyplot as plt
- ** python 에서 실행해야 한다. **
#대표적인 그래프 함수
- plt.plot(np.logspace(0,1,20)) #선그래프- plt.plot(np.logspace(0,1,20),"o") #점그래프 "o"
- plt.hist(np.logspace(0,1,20),bins=100) #hist 막대그래프
- plt.hist(np.random.normal(0,1,20)) #hist 막대그래프
- plt.hist(np.random.rand(1000),bins=100) #hist 막대그래프
#그래프 출력 및 이미지 저장
- plt.plot(np.logspace(0,1,20)) #선그래프- plt.savefig('n12.png') #이미지 저장
- plt.grid(True) #격자표시
- plt.show() #그래프 실행
** lsts = [[i+x for i in range(8)] for x in range(6)] #(6,8) list arr
- for문을 활용하여 2차원 형태의 리스트 배열도 손 쉽게 생성 가능하다.
#13slicing_indexing - 슬라아싱, 인덱싱
#인덱스[r_index , c_index] : 특정 위치를 지목하여 데이터 접근 (0번, 1번방 접근)
#슬라이싱[start : end : (step)] : 특정 범위를 지목하여 데이터들에게 접근(3~10번까지 접근)
#슬라이싱은 원본의 특정 구간을 빌려 쓰기 때문에 해당 내용이 변경되면 원본에 영향을 미치나, 인덱싱은 복사 개념으로 원본에 영향이 없다.
- 슬라이싱과 인덱싱은 서로 비슷하지만, 조금 다르다.#슬라이싱 : ndarray row + col slicing 2차원배열
- 슬라이싱된 데이터들은 원본 데이터와 주소가 같아, 단일 값 변경은 원본에도 영향을 미친다.
- 단, 값을 변경하여 재할 당하는 경우, 별도의 데이터가 된다.- print(arrs[0:,0:]) #all rows, all cols
- print(arrs[0:,:3]) #all rows, [0~2]cols
- print(arrs[0:,0:3] *10) #broadcast 특성 활용#인덱싱 : ndarray row + col indexing 2차원배열
- 특정 값을 하나씩 뽑아올 수 있다.
- 인덱싱된 데이터는 별도로 복사된 데이터로, 값 변경이 원본에 영향을 미치지 않는다.
- print(arrs[[0,2],]) #only 0,2 row
- print(arrs[:,[0,2]]) #only 0,2 col
- print(arrs[[0,2],[0,2]]) #[0,0],[2,2] >> [0,18]
- print(arrs[[3,5,2],[3,6,0]]) #[27,46,16]
#np.tile(반복대상,반복횟수) :하나의 덩어리를 타일(tile)로 보고 반복해서 쌓을 수 있다.
- print(np.tile(arr,5)) #1차원 배열
- print(np.tile(arr,(5,1))) #2차원 배열
#np.repeat(반복대상,반복횟수) :하나의 덩어리를 반복해서 쌓을 수 있다.
- print(np.repeat(arr,5)) #1차원 배열#14boolean_filtering - 불린 필터링
#boolean indexing : 조건을 통해 참인 값을 뽑아낼 수 있다.
- print(arr[arr>5]) #boolean indexing
#boolean where(arr>3) 1차원 배열 : 각 인덱스별로 비교 연산 후, 참인 인덱스 값을 반환
- print(np.where(arr>3))
**각 인덱스별로 비교 연산 후, 삼항 연산처럼 값을 반환 시킬 수 있다.
- print(np.where(arr>3,1,0))
- print(np.where(arr>3,10,arr)) #참인 데이터를 10으로 대체
- print(np.where(arr>3,True,False))
#boolean where(arr>3) 2차원 배열
- print(np.where(temp>3,True,False))
- print(np.where(temp[0]>3,True,False)) #인덱스가 들어갈 수 있다.
#boolean 배열로 슬라이싱 : boolean 배열의 참 행 위치만 가져오기.
- bool_arr = np.array([True for i in range(10)]) #[True,True,,,True]
>>print(arr[bool_arr]) #전체 데이터
- bool_arr = np.array([True if i%2 ==0 else False for i in range(10)]) #[True,False,True,False,,,]
>> print(arr[bool_arr]) #true 위치만 반환
#15trim_zeros_split - 0값 제거, 배열 분할
#trim_zeros(arr) : 시작과 끝 쪽의 0값 제거
- print(np.trim_zeros(arr)) #앞, 뒤에 0값을 배제하고 싶다.
#split(arr) : 배열 쪼개기
- print(np.split(arr,3))
>> print(np.split(arr,3)[0]) #인덱스 접근을 통해 특정 행 추출 가능
- sus1,sus2,sus3 = np.split(arr,3)
>>print(sus1) #변수에 할당하여 특정 행 활용 가능
#배열 수평(horizontal) 쪼개기
- sus1,sus2 = np.hsplit(arr,2)
#배열 수직(vertical) 쪼개기
- sus1,sus2 = np.vsplit(arr,2)
#stack : 배열 합치기
- tuple 형식으로 넣어줘야 함.
- arr = np.hstack(([1,2,3],[4,5,6])) #[1,2,3,4,5,6] >> 1차원 배열
- arr = np.vstack(([1,2,3],[4,5,6])) #[[1,2,3],[4,5,6]] >> 2차원 배열
#16random - 난수 생성
<random.rand>
#0~1사이의 난수로 행렬 생성
- print(np.random.rand(10))
>>print(arr[arr>5]) #boolean indexing : 조건을 통해 값을 뽑아낼 수 있다.
<random.normal>#normal(평균, 표준분포, 갯수) : 지정 범위 내에서 지정 갯수의 난수 생성
- print(np.random.normal(0,1,20)) :평균 0/ 분포 1 에서 20개 난수 생성
<random.randint>#0~10 중 한개의 정수 추출(size 미 기재시, 기본 값 1)
- print(np.random.randint(0,10))
<random.choice>
#5이내의 값에서 5개를 뽑아라, false - 중복허용 안함
- print(np.random.choice(5,5,replace=False)) #shuffle
#5이내의 값에서 5개를 뽑아라, True - 중복 허용
- print(np.random.choice(5,5,replace=True)) #shuffle
#17operator - 연산자
#print("-- + -----")
- print(arr1 +10) #[11 22 33 15] #데이터에 각 10을 합산하여 반환
- print(arr1 + arr2) #[ 6 8 10 12]
#print("----add()---")
- print(np.add(arr1, arr2)) #[ 6 8 10 12] #두 배열의 각 값을 합산
#print("----sum()---")
- print(np.sum(np.arange(1,11))) #1~11 합산 = 55
- print(np.arange(1,11).sum()) #55
#print("----cumsum()---")
- print(np.cumsum(np.arange(1,11))) #[1 3 6 10 .. 55] >> 더해지는 상황에서 누적 값 배열
- print(np.arange(1,11).cumsum())
#print("-- - -----")
- print(arr1 -10) #[-9 -8 -7 -6]
- print(arr1 - arr2) #[-4 -4 -4 -4]
#print("-- subtract -----")
- print(np.subtract(arr1,arr2)) #[-4 -4 -4 -4]
#print("----multiply (*)-----")
- print(arr1 * arr2) #[ 5 12 21 32]
- print(np.multiply(arr1,arr2)) #[ 5 12 21 32]
- print(np.cumprod(np.arange(1,11))) #[ 5 12 21 32]
#print("----divide (/)-----")
- print(arr1 / arr2)
- print(np.divide(arr1,arr2))
#print("----floor-----")
- print(np.floor(3.14))#내림
- print(np.floor(np.divide(arr1,arr2)))
- print(np.floor_divide(arr1,arr2))
#print("----ceil-------")
- print(np.ceil(3.14)) #4.00 >> 올림
#print("----rint-------")
- print(np.rint(3.14)) #3.00 >> 반올림
- print(np.rint(3.54)) #4.00 >> 반올림
- print(np.rint(np.divide(arr1,arr2))) #행렬에도 쓸 수있다.
#print("----mod(%)-------")
- print(arr2 % arr1)
- print(np.mod(arr2, arr1)) #나머지 값
#print("----power(**)-------")
- print(arr2 ** arr1)
- print(np.power(arr2, arr1)) #제곱승
#print("----square(self**2)-------")
- print(arr **2)
- print(np.square(arr))#셀제곱
#print("----sqrt(self**(1/2))-------")
- print(arr **(1/2))
- print(np.sqrt(arr))#셀프 제곱근
#print("----dot : 1차원(벡터) 두 개 내적------")
<내적 : 1차원인 두 배열의 인덱스끼리 곱한 후 모두 더한 값>
>>[1~4], [5~8] = 1*5 + 2*6 + 3*7 + 4*8 = 70
- print(arr1 *arr2)
- print(np.sum(arr1 * arr2))
- print(np.dot(arr1 , arr2))
- print(arr1.dot(arr2))
<dot : 2차원(매트릭스) + 1차원(벡터) 두 개 내적>
>> [1*1 + 2*2 , 3*1 + 4*2]
- print(np.dot(arrs, arr))
- print(arrs.dot(arr),np.sum(arrs.dot(arr)))
<dot : 2차원(매트릭스) + 2차원(매트릭스) 두 개 내적>
>> [1*5 + 2*7 , 1*6 + 2*8] = [19,22]
>> [3*5 + 4*7 , 3*6 + 4*8] = [43,50]
- print(np.dot(arrs1, arrs2))
- print(arrs1.dot(arrs2))
#print("----unique 중복 값 제거----")
- print("ranSus_Unique:",np.unique(ranSus))
#print("----intersect1d 교집합----")
- print("intersect1d",np.intersect1d(ranSus1,ranSus2)) #중복 값은 자동 제외, 값 정렬
#print("----union1d 합집합----")
- print("union1d",np.union1d(ranSus1,ranSus2)) #중복 값은 자동 제외, 값 정렬
** 시각화 창 안닫히면 사용하는 명령어
- ps -ef | grep np12lin*
>> kill -9 xxxx
#12linspace - 그래프그리기
#그래프 작성 준비
#sudo apt update
#sudo apt upgrade
#sudo apt install python-pip
#sudo apt install python-matplotlib
#wget https://pypi.python.org/packages/source/d/drawnow/drawnow-0.44.tar.gz
#ls >> drawnow-0.44.tar.gz
#tar -zxvf drawnow-0.44.tar.gz
#cd drawnow-0.44
#sudo python setup.py install (python 으로 실행할 것. python3 아님)
#sudo pip install drawnow
#cd ..
#python np12linspace.py
#import matplotlib.pyplot as plt
- ** python 에서 실행해야 한다. **
#대표적인 그래프 함수
- plt.plot(np.logspace(0,1,20)) #선그래프
- plt.plot(np.logspace(0,1,20),"o") #점그래프 "o"
- plt.hist(np.logspace(0,1,20),bins=100) #hist 막대그래프
- plt.hist(np.random.normal(0,1,20)) #hist 막대그래프
- plt.hist(np.random.rand(1000),bins=100) #hist 막대그래프
#그래프 출력 및 이미지 저장
- plt.plot(np.logspace(0,1,20)) #선그래프
- plt.savefig('n12.png') #이미지 저장
- plt.grid(True) #격자표시
- plt.show() #그래프 실행



--예문 코드 보기--
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
print("numpy version",np.__version__) #numpy version check
print("--np.linspace(시작값,끝값,분할 갯수) : 1차원 배열--")
print(np.linspace(0,9,5))
print("---------------")
print(np.linspace(0,1,20))
print("--np.linspace((시작값s),(끝값s),분할 갯수) : 2차원 배열--")
print(np.linspace((2,3,4),(7,8,9),5))
print("---------------")
print(np.linspace((2,3,4),(7,8,9),10))
print("--np.logspace((시작값s),(끝값s),분할 갯수) : 2차원 배열--")
#linspace와 비슷하지만 조금더 정교함
print(np.linspace(0,1,20))
print("---------------")
print(np.logspace((2,3,4),(7,8,9),10))
print("---------------")
import matplotlib.pyplot as plt
plt.plot(np.logspace(0,1,20)) #선그래프
#plt.savefig('n12.png') #이미지 저장
plt.grid(True) #격자표시
plt.show()
plt.plot(np.logspace(0,1,20),"o") #점그래프 "o"
#plt.savefig('n12.png')
plt.grid(True)
plt.show()
plt.hist(np.logspace(0,1,20),bins=100) #hist 막대그래프
#plt.savefig('n12.png')
plt.grid(True)
plt.show()
plt.hist(np.random.normal(0,1,20)) #hist 막대그래프
#plt.savefig('n12.png')
plt.grid(True)
plt.show()
plt.hist(np.random.rand(1000),bins=100) #hist 막대그래프
plt.savefig('n12.png')
plt.grid(True)
plt.show()
#sudo apt update
#sudo apt upgrade
#sudo apt install python-pip
#sudo apt install python-matplotlib
#wget https://pypi.python.org/packages/source/d/drawnow/drawnow-0.44.tar.gz
#ls >> drawnow-0.44.tar.gz
#tar -zxvf drawnow-0.44.tar.gz
#cd drawnow-0.44
#sudo python setup.py install #python 으로 실행할 것. python3 아님
#sudo pip install drawnow
#cd ..
#python np12linspace.py
#시각화 창 안닫히면 사용
#ps -ef | grep np12lin*
#kill -9 xxxx
** lsts = [[i+x for i in range(8)] for x in range(6)] #(6,8) list arr
- for문을 활용하여 2차원 형태의 리스트 배열도 손 쉽게 생성 가능하다.
#13slicing_indexing - 슬라아싱, 인덱싱
#인덱스[r_index , c_index] : 특정 위치를 지목하여 데이터 접근 (0번, 1번방 접근)
#슬라이싱[start : end : (step)] : 특정 범위를 지목하여 데이터들에게 접근(3~10번까지 접근)
#슬라이싱은 원본의 특정 구간을 빌려 쓰기 때문에 해당 내용이 변경되면 원본에 영향을 미치나, 인덱싱은 복사 개념으로 원본에 영향이 없다.
- 슬라이싱과 인덱싱은 서로 비슷하지만, 조금 다르다.
#슬라이싱 : ndarray row + col slicing 2차원배열
- 슬라이싱된 데이터들은 원본 데이터와 주소가 같아, 단일 값 변경은 원본에도 영향을 미친다.
- 단, 값을 변경하여 재할 당하는 경우, 별도의 데이터가 된다.
- print(arrs[0:,0:]) #all rows, all cols
- print(arrs[0:,:3]) #all rows, [0~2]cols
- print(arrs[0:,0:3] *10) #broadcast 특성 활용
#인덱싱 : ndarray row + col indexing 2차원배열
- 특정 값을 하나씩 뽑아올 수 있다.
- 인덱싱된 데이터는 별도로 복사된 데이터로, 값 변경이 원본에 영향을 미치지 않는다.
- print(arrs[[0,2],]) #only 0,2 row
- print(arrs[:,[0,2]]) #only 0,2 col
- print(arrs[[0,2],[0,2]]) #[0,0],[2,2] >> [0,18]
- print(arrs[[3,5,2],[3,6,0]]) #[27,46,16]
#np.tile(반복대상,반복횟수) :하나의 덩어리를 타일(tile)로 보고 반복해서 쌓을 수 있다.
- print(np.tile(arr,5)) #1차원 배열
- print(np.tile(arr,(5,1))) #2차원 배열
#np.repeat(반복대상,반복횟수) :하나의 덩어리를 반복해서 쌓을 수 있다.
- print(np.repeat(arr,5)) #1차원 배열




--예문 코드 보기--
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
print("numpy version",np.__version__) #numpy version check
print("---------------")
#슬라이싱은 원본의 특정 구간을 빌려 쓰기 때문에 해당 내용이 변경되면 원본에 영향을 미친다.
#인덱싱은 복사 개념으로 원본에 영향이 없다.
#슬라이싱과 인덱싱이 비슷해보이지만, 조금 다르다.
#0번방 접근, 1번방 접근 - 인덱스 / [3:10] - 슬라이싱
print("---list slicing-----")
lst = [i for i in range(12)]
print(lst)
print(lst[0:]) #all
print(lst[:10]) #[0~9]
print(lst[0:10]) #[0~9]
print(lst[3:10]) #[3~9]
print(lst[3:10:2]) #[3,5,7,9]
print("---list 2차원배열 slicing-----")
lsts = [[i+x for i in range(8)] for x in range(6)] #(6,8) list arr
print(lsts)
print(lsts[0:3])
#print(lsts[0:3,0:3]) #error
print("---ndarray slicing-----")
arr = np.arange(12)
print(arr)
print(arr[0:]) #all
print(arr[:10]) #[0~9]
print(arr[0:10]) #[0~9]
print(arr[3:10]) #[3~9]
print(arr[3:10:2]) #[3,5,7,9]
print("---2차원배열 row slicing-----")
#6행,8열
arrs = np.arange(48).reshape(6,8)
print(arrs)
print(arrs[0:]) #all rows
print(arrs[:4]) #[0~3]
print(arrs[2:4]) #[2~3]
print(arrs[::2]) #0:end:2step
print("---2차원배열 row + col slicing-----")
#6행,8열
arrs = np.arange(48).reshape(6,8)
print(arrs)
print(arrs[0:,0:]) #all rows, all cols
print(arrs[0:,:3]) #all rows, [0~2]cols
print(arrs[0:,0:3] *10)
print(arrs)
tmp = arrs[0:,0:3]
#슬라이싱된 데이터들은 원본 데이터와 주소가 같아, 단일 값 변경은 원본에도 영향을 미친다.
tmp[0][0] = 1000
print(tmp)
print(arrs)
#브로드캐스트 특성 테스트 좀 해보자
print("---ndarray row indexing-----")
arrs = np.arange(48).reshape(6,8)
print(arrs)
print(arrs[0]) #only 0 row
print(arrs[2]) #only 2 row
print(arrs[[0,2],]) #only 0,2 row
tmp = arrs[[0,2],]
#인덱싱된 데이터는 별도로 복사된 데이터로, 값 변경이 원본에 영향을 미치지 않는다.
tmp[0][0] = 1000
print(tmp)
print(arrs)
print("---ndarray col indexing-----")
arrs = np.arange(48).reshape(6,8)
print(arrs)
print(arrs[:,0]) #only 0 col
print(arrs[:,2]) #only 2 col
print(arrs[:,[0,2]]) #only 2 col
print("---ndarray cell(row&col) indexing-----")
#특정 값을 하나씩 뽑아올 수 있다.
arrs = np.arange(48).reshape(6,8)
print(arrs)
print(arrs[[0,2],[0,2]]) #[0,0],[2,2] >> [0,18]
print(arrs[[3,5,2],[3,6,0]]) #[27,46,16]
print("---ndarray cell(row&col) indexing-----")
#특정 값을 하나씩 뽑아올 수 있다.
arrs = np.arange(48).reshape(6,8)
print(arrs)
#둘 다 0을 가져올 수 있다.
print(arrs[0,0], arrs[0][0])
print(arrs[2,2], arrs[2][2])
print(np.array([arrs[0,0],arrs[2,2]])) #[0,18] -길어지지만 가독성은 좋다.
print("---------------")
#arr = np.array([0,1,2]+[0,1,2])
arr = np.array([i for x in range(2)
for i in range(3)])
#arr = np.array([i for x in range(5) for i in range(5)])
print(arr)
print(arr.reshape(2,3))
print("---------------")
arr = np.array([i for x in range(5) for i in range(5)])
print(arr)
print(arr.reshape(5,5))
print("---np.tile(arr,5)-----")
#하나의 덩어리를 타일(tile)로 보고 반복해서 쌓을 수 있다.
arr = np.array([i for i in range(5)])
print(arr)
print(np.tile(arr,5)) #1차원 배열
print(np.tile(arr,(5,1))) #2차원 배열
#print(np.tile(arr,(5,2))) #2차원 배열
print("---------------")
arrs = np.tile(arr,(5,1))
print(arrs[:,0]) #[0 0 0 0 0]
print("---------------")
arrs = np.tile(arr,(5,1)).T
print(arrs)
print(arrs[0]) #[0 0 0 0 0]
print("---------------")
arrs = np.tile(arr,(5,1)).T
print(arrs)
print(np.ravel(arrs)) #[0 0 0 0 0]
print("---------------")
arr = np.array([x for x in range(5)
for i in range(5)])
print(arr)
print("---np.repeat(arr,5)-----")
#하나의 덩어리를 타일(tile)로 보고 반복해서 쌓을 수 있다.
arr = np.array([i for i in range(5)])
print(arr)
print(np.repeat(arr,5)) #1차원 배열
#14boolean_filtering - 불린 필터링
#boolean indexing : 조건을 통해 참인 값을 뽑아낼 수 있다.
- print(arr[arr>5]) #boolean indexing
#boolean where(arr>3) 1차원 배열 : 각 인덱스별로 비교 연산 후, 참인 인덱스 값을 반환
- print(np.where(arr>3))
**각 인덱스별로 비교 연산 후, 삼항 연산처럼 값을 반환 시킬 수 있다.
- print(np.where(arr>3,1,0))
- print(np.where(arr>3,10,arr)) #참인 데이터를 10으로 대체
- print(np.where(arr>3,True,False))
#boolean where(arr>3) 2차원 배열
- print(np.where(temp>3,True,False))
- print(np.where(temp[0]>3,True,False)) #인덱스가 들어갈 수 있다.
#boolean 배열로 슬라이싱 : boolean 배열의 참 행 위치만 가져오기.
- bool_arr = np.array([True for i in range(10)]) #[True,True,,,True]
>>print(arr[bool_arr]) #전체 데이터
- bool_arr = np.array([True if i%2 ==0 else False for i in range(10)]) #[True,False,True,False,,,]
>> print(arr[bool_arr]) #true 위치만 반환


--예문 코드 보기--
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
print("numpy version",np.__version__) #numpy version check
print("----boolean indexing------")
print(np.random.rand(10))
print(np.random.rand(10)*10)
arr = np.int32(np.random.rand(10)*10)
print(arr)
print(arr[arr>5]) #boolean indexing : 조건을 통해 참인 값을 뽑아낼 수 있다.
print("----boolean where(arr>3) 1차원 배열----")
#각 인덱스별로 비교 연산 후, 참인 인덱스 값을 반환
print(np.where(arr>3))
#각 인덱스별로 비교 연산 후, 삼항 연산처럼 값을 반환 시킬 수 있다.
print(np.where(arr>3,1,0))
print(np.where(arr>3,10,arr)) #참인 데이터를 10으로 대체
print(np.where(arr>3,True,False))
print("--- boolean where(arr>3) 2차원 배열------")
temp = arr.reshape(2,5)
print(temp)
print(np.where(temp>3,True,False))
print("---------------")
print(np.where(temp[0]>3,True,False)) #인덱스가 들어갈 수 있다.
print(np.where(temp[1]>3,True,False)) #인덱스가 들어갈 수 있다.
print("-------boolean 배열로 슬라이싱--------")
arr = np.arange(50).reshape(10,5)
print(arr)
#참 행만 가져오기.
bool_arr = np.array([True for i in range(10)]) #[True,True,,,True]
print(bool_arr)
print(arr[bool_arr])
print("---------------")
#참 행만 가져오기.
bool_arr = np.array([True if i%2 ==0 else False
for i in range(10)]) #[True,False,True,False,,,]
print(bool_arr)
print(arr[bool_arr])
print("---------------")
#15trim_zeros_split - 0값 제거, 배열 분할
#trim_zeros(arr) : 시작과 끝 쪽의 0값 제거
- print(np.trim_zeros(arr)) #앞, 뒤에 0값을 배제하고 싶다.
#split(arr) : 배열 쪼개기
- print(np.split(arr,3))
>> print(np.split(arr,3)[0]) #인덱스 접근을 통해 특정 행 추출 가능
- sus1,sus2,sus3 = np.split(arr,3)
>>print(sus1) #변수에 할당하여 특정 행 활용 가능
#배열 수평(horizontal) 쪼개기
- sus1,sus2 = np.hsplit(arr,2)
#배열 수직(vertical) 쪼개기
- sus1,sus2 = np.vsplit(arr,2)
#stack : 배열 합치기
- tuple 형식으로 넣어줘야 함.
- arr = np.hstack(([1,2,3],[4,5,6])) #[1,2,3,4,5,6] >> 1차원 배열
- arr = np.vstack(([1,2,3],[4,5,6])) #[[1,2,3],[4,5,6]] >> 2차원 배열


--예문 코드 보기--
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
print("numpy version",np.__version__) #numpy version check
print("----trim_zeros(arr)----")
#시작과 끝 쪽의 0값 제거
arr = np.array([0,0,1,2,0,9,0,0])
print(arr)
print(np.trim_zeros(arr)) #앞, 뒤에 0값을 배제하고 싶다.
print("----split(arr)----")
#배열 쪼개기
arr = np.array([0,0,1,2,0,9,0,0])
print(arr)
print(np.split(arr,2))
arr = np.arange(12)
print(arr)
print(np.split(arr,3))
print(np.split(arr,3)[0]) #인덱스 접근
print(np.split(arr,3)[1])
print(np.split(arr,3)[2])
print("----배열 쪼개기 응용----")
arr = np.arange(12)
print(arr)
sus1,sus2,sus3 = np.split(arr,3)
print(sus1) #변수에 할당하여 접근
print(sus2)
print(sus3)
print("----배열 수평(horizontal) 쪼개기----")
arr = np.arange(48).reshape(6,8)
print(arr)
sus1,sus2 = np.hsplit(arr,2)
print(sus1) #변수에 할당하여 접근
print(sus2)
print("----배열 수직(vertical) 쪼개기----")
arr = np.arange(48).reshape(6,8)
print(arr)
sus1,sus2 = np.vsplit(arr,2)
print(sus1) #변수에 할당하여 접근
print(sus2)
print("----stack : 배열 합치기----")
arr = np.array([1,2,3]+[4,5,6])
print(arr)
#tuple 형식으로 넣어줘야 함.
arr = np.hstack(([1,2,3],[4,5,6])) #1차원 배열이 된다. [1,2,3,4,5,6]
print(arr)
arr = np.vstack(([1,2,3],[4,5,6])) #2차원 배열이 된다. [[1,2,3],[4,5,6]]
print(arr)
#16random - 난수 생성
<random.rand>
#0~1사이의 난수로 행렬 생성
- print(np.random.rand(10))
>>print(arr[arr>5]) #boolean indexing : 조건을 통해 값을 뽑아낼 수 있다.
<random.normal>
#normal(평균, 표준분포, 갯수) : 지정 범위 내에서 지정 갯수의 난수 생성
- print(np.random.normal(0,1,20)) :평균 0/ 분포 1 에서 20개 난수 생성
<random.randint>
#0~10 중 한개의 정수 추출(size 미 기재시, 기본 값 1)
- print(np.random.randint(0,10))
<random.choice>
#5이내의 값에서 5개를 뽑아라, false - 중복허용 안함
- print(np.random.choice(5,5,replace=False)) #shuffle
#5이내의 값에서 5개를 뽑아라, True - 중복 허용
- print(np.random.choice(5,5,replace=True)) #shuffle


--예문 코드 보기--
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
print("numpy version",np.__version__) #numpy version check
print("---------------")
print("----boolean indexing------")
print(np.random.rand(10))
print(np.random.rand(10)*10)
arr = np.int32(np.random.rand(10)*10)
print(arr)
print(arr[arr>5]) #boolean indexing : 조건을 통해 값을 뽑아낼 수 있다.
print("----random.normal----")
print(np.random.normal(0,1,20))
print(np.random.normal(1,100,20))
print("----random.randint----")
print(np.random.randint(0,10)) #choice one
print("----random.choice----")
#5이내의 값에서 5개를 뽑아라, false - 중복허용 안함
print(np.random.choice(5,5,replace=False)) #shuffle
lst = [10,100,1000,10000]
lst = ['10','A','J','Q','K']
print(np.random.choice(lst,5,replace=False)) #shuffle
print("----choice----")
#5이내의 값에서 5개를 뽑아라, True - 중복 허용
print(np.random.choice(5,5,replace=True)) #shuffle
lst = ['10','A','J','Q','K']
print(np.random.choice(lst,5,replace=True)) #shuffle
#17operator - 연산자
#print("-- + -----")
- print(arr1 +10) #[11 22 33 15] #데이터에 각 10을 합산하여 반환
- print(arr1 + arr2) #[ 6 8 10 12]
#print("----add()---")
- print(np.add(arr1, arr2)) #[ 6 8 10 12] #두 배열의 각 값을 합산
#print("----sum()---")
- print(np.sum(np.arange(1,11))) #1~11 합산 = 55
- print(np.arange(1,11).sum()) #55
#print("----cumsum()---")
- print(np.cumsum(np.arange(1,11))) #[1 3 6 10 .. 55] >> 더해지는 상황에서 누적 값 배열
- print(np.arange(1,11).cumsum())
#print("-- - -----")
- print(arr1 -10) #[-9 -8 -7 -6]
- print(arr1 - arr2) #[-4 -4 -4 -4]
#print("-- subtract -----")
- print(np.subtract(arr1,arr2)) #[-4 -4 -4 -4]
#print("----multiply (*)-----")
- print(arr1 * arr2) #[ 5 12 21 32]
- print(np.multiply(arr1,arr2)) #[ 5 12 21 32]
- print(np.cumprod(np.arange(1,11))) #[ 5 12 21 32]
#print("----divide (/)-----")
- print(arr1 / arr2)
- print(np.divide(arr1,arr2))
#print("----floor-----")
- print(np.floor(3.14))#내림
- print(np.floor(np.divide(arr1,arr2)))
- print(np.floor_divide(arr1,arr2))
#print("----ceil-------")
- print(np.ceil(3.14)) #4.00 >> 올림
#print("----rint-------")
- print(np.rint(3.14)) #3.00 >> 반올림
- print(np.rint(3.54)) #4.00 >> 반올림
- print(np.rint(np.divide(arr1,arr2))) #행렬에도 쓸 수있다.
#print("----mod(%)-------")
- print(arr2 % arr1)
- print(np.mod(arr2, arr1)) #나머지 값
#print("----power(**)-------")
- print(arr2 ** arr1)
- print(np.power(arr2, arr1)) #제곱승
#print("----square(self**2)-------")
- print(arr **2)
- print(np.square(arr))#셀제곱
#print("----sqrt(self**(1/2))-------")
- print(arr **(1/2))
- print(np.sqrt(arr))#셀프 제곱근
#print("----dot : 1차원(벡터) 두 개 내적------")
<내적 : 1차원인 두 배열의 인덱스끼리 곱한 후 모두 더한 값>
>>[1~4], [5~8] = 1*5 + 2*6 + 3*7 + 4*8 = 70
- print(arr1 *arr2)
- print(np.sum(arr1 * arr2))
- print(np.dot(arr1 , arr2))
- print(arr1.dot(arr2))
<dot : 2차원(매트릭스) + 1차원(벡터) 두 개 내적>
>> [1*1 + 2*2 , 3*1 + 4*2]
- print(np.dot(arrs, arr))
- print(arrs.dot(arr),np.sum(arrs.dot(arr)))
<dot : 2차원(매트릭스) + 2차원(매트릭스) 두 개 내적>
>> [1*5 + 2*7 , 1*6 + 2*8] = [19,22]
>> [3*5 + 4*7 , 3*6 + 4*8] = [43,50]
- print(np.dot(arrs1, arrs2))
- print(arrs1.dot(arrs2))
#print("----unique 중복 값 제거----")
- print("ranSus_Unique:",np.unique(ranSus))
#print("----intersect1d 교집합----")
- print("intersect1d",np.intersect1d(ranSus1,ranSus2)) #중복 값은 자동 제외, 값 정렬
#print("----union1d 합집합----")
- print("union1d",np.union1d(ranSus1,ranSus2)) #중복 값은 자동 제외, 값 정렬


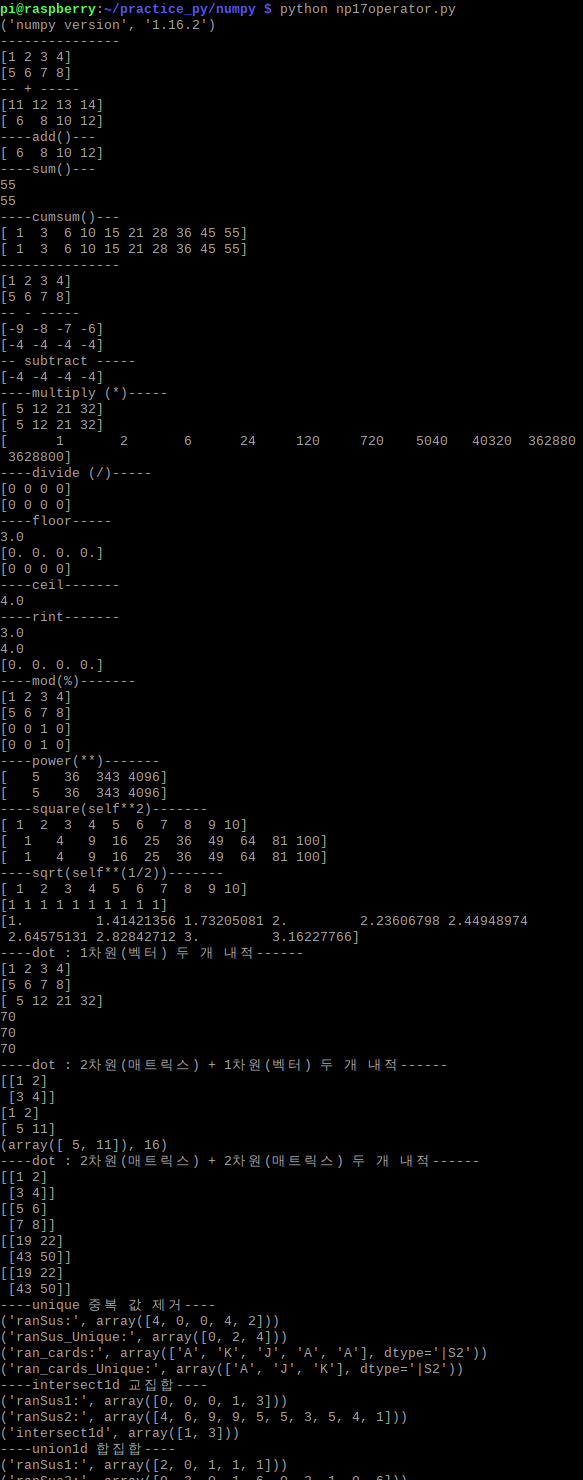
--예문 코드 보기--
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
print("numpy version",np.__version__) #numpy version check
print("---------------")
arr1 = np.arange(1,5,1)
print(arr1)
arr2 = np.arange(5,9,1)
print(arr2)
print("-- + -----")
print(arr1 +10) #[11 22 33 15]
print(arr1 + arr2) #[ 6 8 10 12]
print("----add()---")
print(np.add(arr1, arr2)) #[ 6 8 10 12]
print("----sum()---")
print(np.sum(np.arange(1,11))) #[ 6 8 10 12]
print(np.arange(1,11).sum()) #[ 6 8 10 12]
print("----cumsum()---")
print(np.cumsum(np.arange(1,11))) #더해지는 상황에서 누적 값 배열
print(np.arange(1,11).cumsum())
print("---------------")
arr1 = np.arange(1,5,1)
print(arr1)
arr2 = np.arange(5,9,1)
print(arr2)
print("-- - -----")
print(arr1 -10) #[-9 -8 -7 -6]
print(arr1 - arr2) #[-4 -4 -4 -4]
print("-- subtract -----")
print(np.subtract(arr1,arr2)) #[-4 -4 -4 -4]
print("----multiply (*)-----")
print(arr1 * arr2) #[ 5 12 21 32]
print(np.multiply(arr1,arr2)) #[ 5 12 21 32]
print(np.cumprod(np.arange(1,11))) #[ 5 12 21 32]
print("----divide (/)-----")
print(arr1 / arr2)
print(np.divide(arr1,arr2))
print("----floor-----")
print(np.floor(3.14))#내림
print(np.floor(np.divide(arr1,arr2)))
print(np.floor_divide(arr1,arr2))
print("----ceil-------")
print(np.ceil(3.14)) #올림
print("----rint-------")
print(np.rint(3.14)) #반올림
print(np.rint(3.54)) #반올림
print(np.rint(np.divide(arr1,arr2))) #행렬에도 쓸 수있다.
print("----mod(%)-------")
arr1 = np.arange(1,5,1)
print(arr1)
arr2 = np.arange(5,9,1)
print(arr2)
print(arr2 % arr1)
print(np.mod(arr2, arr1)) #나머지 값
print("----power(**)-------")
print(arr2 ** arr1)
print(np.power(arr2, arr1)) #제곱승
print("----square(self**2)-------")
arr = np.arange(1,10+1)
print(arr)
print(arr **2)
print(np.square(arr))#셀제곱
print("----sqrt(self**(1/2))-------")
arr = np.arange(1,10+1)
print(arr)
print(arr **(1/2))
print(np.sqrt(arr))#셀프 제곱근
print("----dot : 1차원(벡터) 두 개 내적------")
arr1 = np.arange(1,5,1)
print(arr1)
arr2 = np.arange(5,9,1)
print(arr2)
#내적 : 1차원인 두 배열의 인덱스끼리 곱한 후 모두 더한 값
#1*5 + 2*6 + 3*7 + 4*8 = 70
print(arr1 *arr2)
print(np.sum(arr1 * arr2))
print(np.dot(arr1 , arr2))
print(arr1.dot(arr2))
print("----dot : 2차원(매트릭스) + 1차원(벡터) 두 개 내적------")
arrs = np.arange(1,4+1).reshape(2,2)
print(arrs)
arr = np.arange(1,1+2)
print(arr)
#[1*1 + 2*2 , 3*1 + 4*2]
print(np.dot(arrs, arr))
print(arrs.dot(arr),np.sum(arrs.dot(arr)))
print("----dot : 2차원(매트릭스) + 2차원(매트릭스) 두 개 내적------")
arrs1 = np.arange(1,4+1).reshape(2,2)
print(arrs1)
arrs2 = np.arange(5,8+1).reshape(2,2)
print(arrs2)
#[1*5 + 2*7 , 1*6 + 2*8] = [19,22]
#[3*5 + 4*7 , 3*6 + 4*8] = [43,50]
print(np.dot(arrs1, arrs2))
print(arrs1.dot(arrs2))
print("----unique 중복 값 제거----")
ranSus = np.random.choice(5,5,replace=True)
print("ranSus:",ranSus)
print("ranSus_Unique:",np.unique(ranSus))
lst = ['10','A','J','Q','K']
ran_cards = np.random.choice(lst,5,replace=True)
print("ran_cards:",ran_cards)
print("ran_cards_Unique:",np.unique(ran_cards))
print("----intersect1d 교집합----")
ranSus1 = np.random.choice(5,5,replace=True)
ranSus2 = np.random.choice(10,10,replace=True)
print("ranSus1:",ranSus1)
print("ranSus2:",ranSus2)
print("intersect1d",np.intersect1d(ranSus1,ranSus2)) #중복 값은 자동 제외, 값 정렬
print("----union1d 합집합----")
ranSus1 = np.random.choice(5,5,replace=True)
ranSus2 = np.random.choice(10,10,replace=True)
print("ranSus1:",ranSus1)
print("ranSus2:",ranSus2)
print("union1d",np.union1d(ranSus1,ranSus2)) #중복 값은 자동 제외, 값 정렬


